
Your words stay in-house
Most businesses evaluating TTS (Text-to-speech, or Voice Synthesis) share most of these requirements:
- On-premises: text never leaves the machine, no API calls, no third-party data exposure
- Quality: natural enough to actually listen to, not the robotic cadence of classic TTS
- Multilingual: able to speak the native language of employees
- Streaming / batch: realtime speech for interactive use, or file output for longer content
- Permissive license: usable commercially without negotiation
- Forecastable cost: infrastructure spend is fixed and predictable, with no exposure to vendor pricing changes
This post is a report of how well TTS technologies I reviewed and work with deal with these requirements.
Adoption drivers
Privacy by architecture
With a self-hosted TTS service, the text being synthesized never leaves your infrastructure.
No API call to OpenAI, Google, or ElevenLabs. No terms-of-service clause about training data. No audit trail at a third party. For businesses handling sensitive documents, customer communications, legal content, or regulated data, this removes an entire category of risk.
Cost that scales with hardware, not usage
Cloud TTS is priced per character. At volume (automated reports, customer notifications, content libraries, call center prompts) the bill compounds fast.
Self-hosted TTS has a fixed infrastructure cost. Once the GPU is running, synthesizing one sentence or ten thousand costs the same.
Reliability and control
No rate limits, no upstream outages, no deprecation notices. The model you deploy is the model you keep.
What this unlocks
A consistent brand voice across all languages and markets
In many modern TTS models, voice character and language are decoupled. The same narrator reads your content in French, Italian, English, or Japanese, with consistent timbre throughout. No per-market voice casting, no coordination across regional teams.

Tone on demand
Voices accept a plain-language instruction alongside the text to read.
"Speak slowly and warmly, as if explaining to someone unfamiliar with the topic."
"Fast-paced and confident, like a professional anchor."
"Calm and reassuring, with deliberate pauses."
Calm for customer support, authoritative for compliance notices, energetic for product announcements. No re-recording, no voice actor availability to manage.
Suitable for regulated and air-gapped environments
Once model weights are downloaded, the system has no external dependencies. Suitable for finance, healthcare, defense, or any context where data cannot leave a controlled environment.
Common questions
"How many channels can run in parallel?"
"What are the harware requirements?"
Exact throughput of concurrent streams on a single GPU depends on the model, available VRAM, and average text length.
What shapes the number:
- Model size: the lighter Qwen3-TTS (1.7B parameters) fits more concurrent requests in the same VRAM budget than the heavier Voxtral (4B).
- Batching: the serving layer uses continuous batching, requests share GPU time rather than queuing one at a time.
- Text length: short utterances (notifications, prompts) allow more parallelism than long-form documents.
- Streaming vs. batch: streaming holds a GPU slot for the duration of synthesis; batch mode frees it immediately.
For a call center or notification system generating short utterances, a single high-end GPU can handle tens of concurrent streams. For a narration pipeline producing long audio files, throughput is lower but latency per job stays predictable.
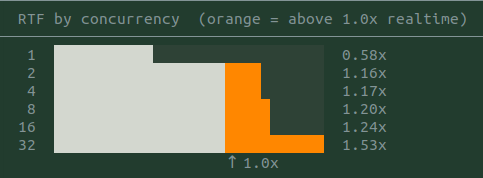
On a mid-range GPU, one voice channel plays in realtime. Running several in parallel is not yet viable on this hardware (RTX 4060 Ti 16GB). The utilization data suggests a modest hardware upgrade would support 16 or more simultaneous channels.
Qwen3-TTS is lighter than Voxtral and can presumably run in a higher number of parallel instances. A transient limitation to the vLLM-Omni libray doesn't allow to test streaming Qwen at the moment.
Comparison
TTS space
Several TTS systems were considered before focusing on Qwen and Voxtral:
- VoxCPM: Multilingual (30+ languages), fast and under Apache 2.0 licence. Voice is defined through a prompt. Demos are very promising. Will put to the test soon.
- Piper: Fast, CPU-only, many voices across many languages. Quality is noticeably lower, closer to classic TTS. Good for resource-constrained deployments (edge, IoT, embedded). Its license is GPL-3.0, that is unusable in most business contexts because it forces to opensource derivative work.
- MeloTTS: Multilingual (EN, ZH, JP, KR, ES, FR), fast on CPU, MIT license. Decent quality but no instruction-following and limited voice variety.
- TADA and LuxTTS: Both voice-cloning systems that require a reference audio file to define the speaker.
- Cloud TTS (OpenAI, ElevenLabs, Google, Azure): Highest quality ceiling, lowest setup cost, but all the privacy and billing trade-offs described above.
License: Qwen3-TTS vs. Voxtral
Qwen3-TTS is the commercially viable choice. Voxtral is ok for internal use, with caution.
Qwen3-TTS: Apache-2.0 throughout (code and weights). No restrictions on commercial or internal use beyond standard attribution.
Voxtral: CC BY-NC 4.0 on the model weights, inherited from voice reference training data (EARS, CML-TTS, IndicVoices-R, Arabic Natural Audio datasets). NC = NonCommercial. Three practical scenarios:
- Pure internal use (internal tools, employee-facing apps, R&D with no connection to a product sold to customers): generally permitted under CC BY-NC 4.0.
- Internal use tied to a commercial activity (e.g. generating voice content that feeds into a product, even if not directly sold): ambiguous, a commercial license from Mistral AI is recommended.
- External product or service: requires a commercial license from Mistral AI.
For unrestricted commercial deployment, Qwen3-TTS (Apache-2.0) is the simpler choice. For strictly internal, non-commercial use, Voxtral is also available.
Confirm with your legal team for your specific scenario. Source: Mistral AI (Le Chat, April 2026).
Available Voices
- Voxtral-4B-TTS-2603: 20 preset voices across 9 languages (English, French, German, Spanish, Italian, Portuguese, Dutch, Arabic, Hindi). Streaming (chunked PCM) supported.
- Qwen3-TTS-12Hz-1.7B-CustomVoice: 9 preset voices, synthesizes any language regardless of the speaker's native language. Strong emotional range and instruction-following.